It is hard to conceptualize how much happens around here - I am looking back at our last newsletter - which was in August and reads like it came from a different world. I don’t know if any of you have worked at a fast-growing/changing/developing project, but it always feels like the Lenin quote:
"There are decades where nothing happens; and there are weeks where decades happen." ― Vladimir Ilyich Lenin
But all the weeks are the ones where decades happen…
Hub allows you to store databases in the cloud, control who can access them, make sure each person has the latest version, easy sync to update, and can be cloned to any computer complete with complex internal structure and metadata (to our sophisticated in-memory analytical engine).
Lossless, compressed data-structures can be queried "in-place" without decompression shared through the internet. It's a kind of magic ;-)
And as all computing is local (on your machine or in your cloud), the economics are good so we have a generous free-forever tier.
Go to TerminusHub to signup (we have easy Google and GitHub authentication) and download TerminusDB to interact with all of the test datasets that we have provided. You can then start to build your own version control ecosystem.
We have a new electron app for windows users and a soon-to-be-released version for Mac users. We know most people will continue to work with TerminusDB via the Python and JavaScript clients - but it always helps to be able to visit a control console
Many ML/AI shops use CSVs + email or slack (or notebooks) for the storage and distribution of both data and features. That creates all sorts of headaches - no version control, just hard to understand suffixes (code in 2001 anybody?); no visibility of what is available or what is shared - just random ‘oh Mary has the output of the GAN on her machine’ information; feature selection is hard to compare and is individual to each experiment, and the CSVs that people share contain no type information so have to be constantly marshaled in and out of formats with repeated cleaning causing all sorts of errors!
Some practitioners try to solve this by using Git itself as a versioning system for data (web scrappers seem to particularly prone to this) - but it is not designed for data, can’t scale with data, can’t hold type information and can’t be queried. We also hear a lot of data-intensive teams say ‘I just work directly on my cloud data warehouse data and it is better to have a single central store’. We think that sounds like code before ‘distributed’ came along. It’s centralized and kills productivity & collaboration.
Here is a hard to read cartoon that explains it from Changying’s perspective (browsers to 200% please):
Share
Here is a video that tries to explain the value prop in less than 90 seconds (made by the excellent Headless Hippies agency - strongly recommend if you need video work):
Since we last spoke, we have joined the DBpedia Association (a project aiming to extract all the structured data from Wikipedia) and the AI Infrastructure Alliance.
TerminusDB took part in the DBpedia Autumn 2020 Hackathon - we tried to enrich the Seshat: Global History Databank data with conflict data taken from DBpedia. It went really well and we produced a step-by-step blog that covers all our work.
You can clone the full DBpedia data set from TerminusHub and run all of the below steps for yourself (for non-technical users - like your correspondent - it is easy to do, here is a video of clone and query in under 3 minutes.
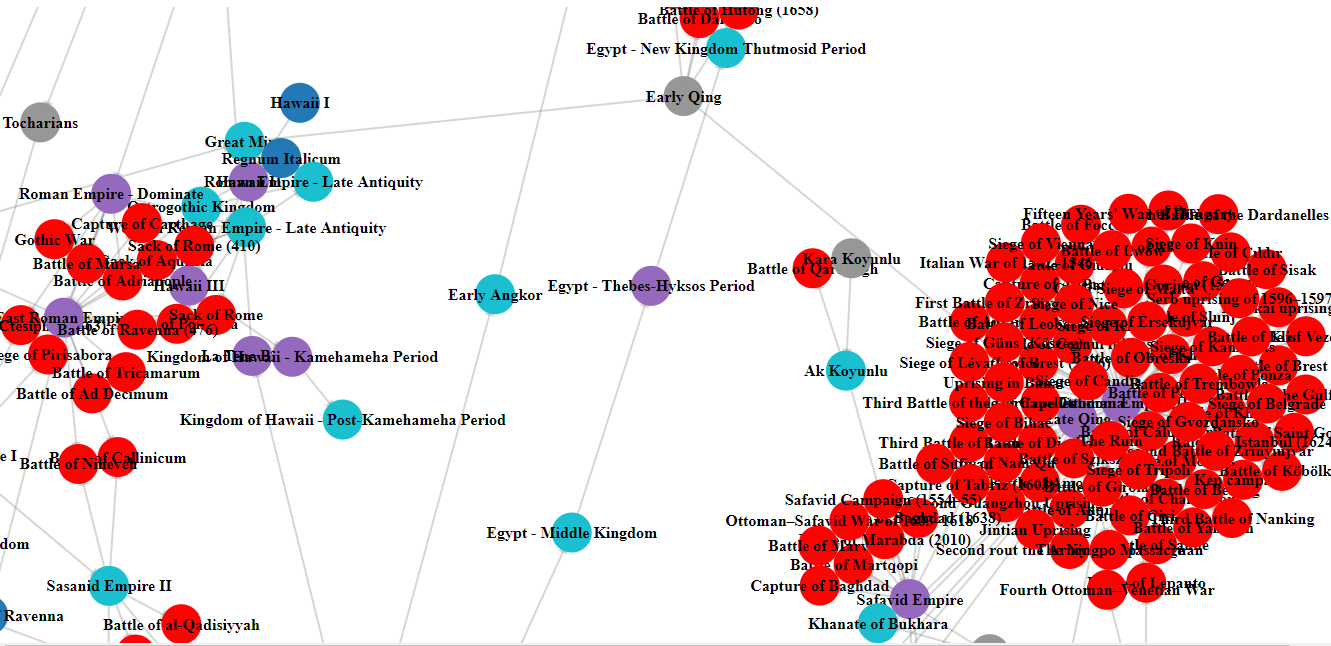
We made a visual at the end of the Hackathon:
You can explore the visualization of conflicts and polities.
*Red - Battle/War/Conflict*
*Purple - polity with a standing army*
*Blue - polity with no standing army*
*Grey - no information about standing army (unknown unknowns)*
*Yellow - known unknown (we know we don’t know)*
The AI Infrastructure Alliance is a group of technologies that is dedicated to bringing together the essential building blocks for the Artificial Intelligence applications of today and tomorrow. We are currently working to define the canonical stack in machine learning and produced this helpful article to get the ball rolling.
Leave a comment
One of the features that we are really excited about is the easy ability to version CSVs using TerminusDB and TerminusHub. We want to be the version control layer for all your data work, so we are making it as easy as possible to marshal CSVs in and out of Terminus. You can automate this process so you just have a backup of versions with commit logs so you can go back to any point in the past with a simple query.
The glorious return of Terminators on Tech was an extensive discussion of CSV versioning with a demonstration included. (Whisper it .xls is coming soon).
A selection of the best new blogs:
Size Matters (a look at our approach to compression)
TerminusDB v Neo4j (a side by side comparison)
The TerminusDB Values (η καρδιά μας)
Collaboration for Structured Data
And a video discussion of Esperanto for good measure
Terminus YouTube
We have a big ongoing project to improve our docs. We had a session in the Discord server to generate titles of all the documentation that would ideally like to see. This is what we came up with:
We are going to have another session in the very near future to actually write the docs - please drop in and give a hand! All contributions will be rewarded with undying loyalty and devotion.
Join Our Discord